Blog • Insights
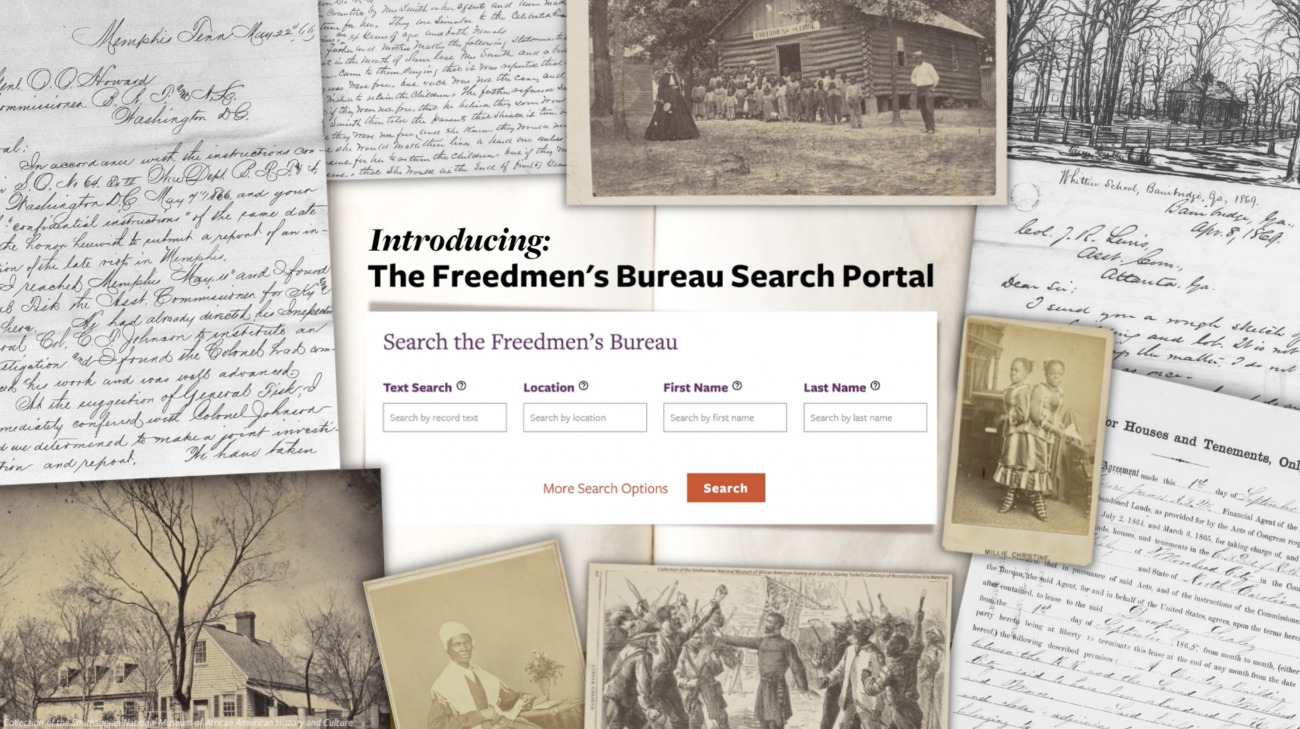
Building Online Portals for Full-Text Searches of Historical Archives
🏆 The Freedmen’s Bureau Search Portal is a 2024 Anthem Awards winner for Best Use of Data in the Education, Arts & Culture Category.
There are billions of historical documents housed in archives, museums, and libraries around the world. The vast majority of these documents do not have full-text transcriptions or indexed data, making them difficult to search and largely inaccessible to historians, students, scholars, and the general public. However, with institutional support and the help of volunteers, these documents can be made available and searchable by anyone on the web. Case in point: the Freedmen’s Bureau Search Portal, produced by the Smithsonian National Museum of African American History and Culture (NMAAHC).
The United States Bureau of Refugees, Freedmen, and Abandoned Lands—more commonly known as the Freedmen’s Bureau—was created by Congress on March 3, 1865. The bureau was responsible for helping formerly enslaved people transition to citizenship and for all matters relating to the refugees, freedmen, and lands abandoned or seized during the Civil War. In the process, millions of federal records were created that recorded the names of these formerly enslaved individuals for the first time.
In 2016 NMAAHC launched the Freedmen’s Bureau Transcription Project in the Smithsonian Transcription Center. Since then, thousands of volunteers have transcribed hundreds of thousands of image files of the more than 1.7 million pages of documents in the Freedmen’s Bureau archive, the largest transcription project ever undertaken by the Smithsonian. To make these files as searchable as possible, NMAAHC teamed up with Forum One and Quotient, to build the Freedmen’s Bureau Search Portal. Through this online portal, anyone can search the transcribed and indexed Freedmen’s Bureau Archive in one place.
Two data sets are used in the search portal. The first set is indexed data (the names, locations, and dates) created in 2015 by volunteers as part of an initiative by NMAAHC, FamilySearch International, the California African American Museum, and the Afro-American Historical and Genealogical Society. The second is the word-for-word transcriptions of each document image created through a crowdsourcing project by NMAAHC and the Smithsonian Transcription Center. The data sets are linked together through the document image files allowing the documents to be searched by first name, last name, date, state, county, city, or any text.
The Freedmen’s Bureau Search Portal was a massive undertaking that could not have happened without the Smithsonian, multiple partners, the thousands of volunteers who transcribed the documents, and the technology that powers the portal. To date, more than half a million pages of records have been transcribed. To help transcribe the remaining documents, please visit the Smithsonian Transcription Center.